



Flujo de eventos de un Checkout distribuido
Cómo diseñar flujos resilientes y desacoplados en un eCommerce composable basado en microservicios

Un Checkout Composable sigue, en general, un flujo de pasos secuenciales distribuidos entre distintos servicios.
Estos servicios se comunican entre sí combinando llamadas API síncronas y eventos asíncronos, buscando siempre el equilibrio entre control y autonomía.
Imaginemos un flujo típico en una arquitectura de microservicios de eCommerce:
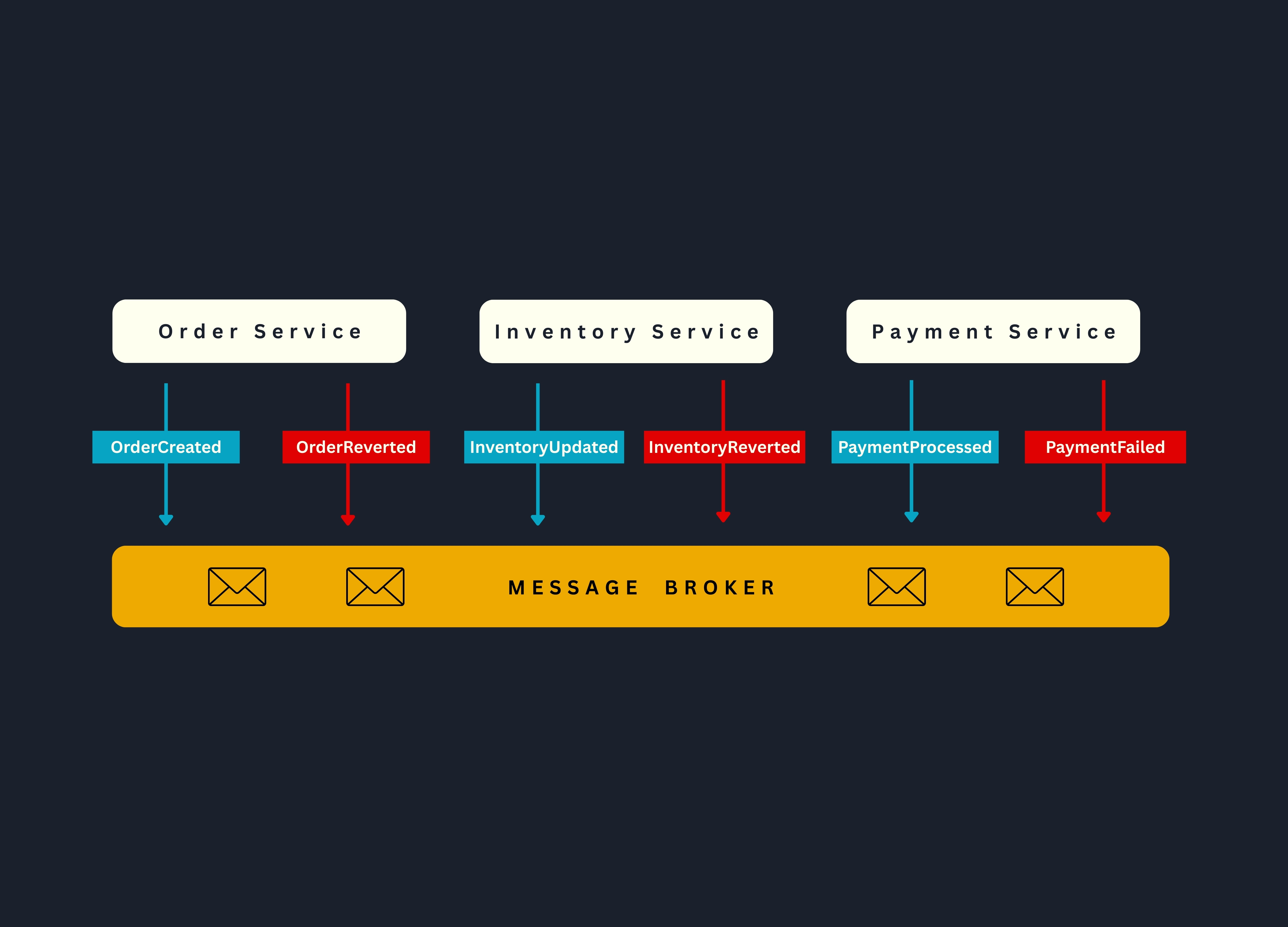
Todo comienza cuando el Order Service publica un evento OrderCreated tras crear una nueva orden. El Inventory Service escucha este evento, realiza una transacción local para reservar stock, y emite a su vez un evento InventoryUpdated.
El Payment Service reacciona entonces, procesando el cobro. Si en algún momento algo falla —por ejemplo, si se rechaza un pago — cada servicio ejecuta una transacción compensatoria para revertir su acción previa y preservar la consistencia del sistema (más sobre como implementar esto en la próxima publicación).
Ahora bien, ¿cómo se articulan estas interacciones? Desde el inicio, el frontend o un backend-for-frontend (BFF) realiza una llamada REST (por ejemplo, POST /orders) para disparar la creación de la orden. A partir de aquí, los servicios pueden integrarse de dos formas principales.
Una opción es la orquestación basada en APIs síncronas: un servicio central, como el Order Service, se encarga de invocar directamente a otros servicios en secuencia —por ejemplo, primero reservar inventario (POST /inventory/reservations) y luego procesar el pago (POST /payments)—. Esta estrategia permite un control explícito del flujo, aunque introduce cierto acoplamiento al orquestador.
La alternativa es la coreografía mediante eventos asíncronos: en lugar de llamadas directas, cada microservicio publica y consume eventos relevantes. Así, el Order Service emite un evento OrderCreated, el Inventory Service lo consume y, tras reservar stock, emite InventoryUpdated, que luego es procesado por el Payment Service para efectuar el cobro. Esta modalidad reduce el acoplamiento y permite que cada servicio opere a su propio ritmo, en un esquema conocido como temporal decoupling.
En la práctica, los sistemas modernos combinan ambos enfoques: pasos críticos como la autorización de pago suelen mantenerse síncronos para obtener una respuesta inmediata, mientras que las actualizaciones de inventario, envíos o notificaciones se manejan de forma asíncrona mediante eventos.
Veamos un ejemplo concreto de secuencia:
Cuando un cliente confirma su carrito, la UI dispara un POST /orders al Order Service, que registra la orden en estado PENDING y publica un evento OrderCreated. El cliente recibe una respuesta inmediata con el ID de la orden, mientras en paralelo el flujo continúa.
El Inventory Service escucha el evento, valida la disponibilidad de stock y, si todo está en orden, lo reserva. Luego emite un evento InventoryUpdated. Si el stock estuviera agotado, en cambio, publicaría un evento de fallo, como InventoryFailed.
El Payment Service, al recibir la confirmación de stock reservado, procesa el cobro —posiblemente invocando una API externa de la pasarela de pagos—. Según el resultado, publicará un evento PaymentProcessed o PaymentFailed.
El Order Service, escuchando estos eventos, actualiza el estado de la orden: la marca como CONFIRMADA si el pago fue exitoso, o como RECHAZADA en caso de fallar. En escenarios orquestados, esta decisión puede tomarse directamente como parte del flujo síncrono.
Una vez confirmada la orden, otros servicios entran en juego: el de envíos crea las guías de transporte, el de notificaciones envía un correo de confirmación, el de loyalty acumula puntos de fidelidad. Todo esto suele orquestarse de forma asíncrona, manteniendo los módulos bien desacoplados.
Es importante notar que en un sistema distribuido como este, ningún servicio tiene una visión completa del flujo de punta a punta. Cada uno cumple su rol y depende de eventos o APIs para comunicarse. Por eso, es fundamental contar con mecanismos de correlación de eventos y trazabilidad de pedidos, así como una estrategia clara para manejar errores en cascada —como liberar el stock reservado si falla el pago—.
Un diagrama de secuencia detallado, que incluya todos los eventos y llamadas API involucradas, será clave como blueprint de implementación para los equipos de desarrollo. Así, todos podrán construir servicios alineados hacia una experiencia de compra robusta y confiable.
Así, en un checkout distribuido, cada servicio actúa de manera independiente, sin una transacción única que los abarque a todos. Pero en un entorno donde los errores pueden surgir en cualquier punto del flujo, mantener la consistencia de datos se vuelve un desafío mayor.
¿Existe una manera de coordinar múltiples servicios para que, aun fallando uno de ellos, todo el sistema siga funcionando de forma confiable?
En la próxima publicación te mostraré cómo resolver este problema crítico en arquitecturas distribuidas.