



Arquitectura de un carrito de compra composable
Modelado, persistencia e integración del Cart Service en arquitectura composable.

Hablar del carrito de compras en una arquitectura composable es mucho más que pensar en una simple lista de productos. Es entrar en el núcleo transaccional del eCommerce moderno, donde backend y frontend se desacoplan estratégicamente para escalar, integrar y evolucionar sin fricciones.
En esta publicación vamos a explorar cómo se diseña un Cart Service robusto, qué decisiones técnicas lo hacen eficiente, y cómo se orquesta su interacción con el resto del ecosistema digital.
Diseño del carrito de compra backend
En una arquitectura headless y composable, el carrito de compras se modela como un servicio backend independiente al que se conectan distintos frontends (web, móvil, apps) mediante APIs.
Esto contrasta con los monolitos tradicionales donde el carrito estaba acoplado al servidor web del eCommerce.
Al desacoplar, el backend centraliza la lógica de carrito (estructura de datos, cálculos, integraciones) y el frontend se limita a consumir esa funcionalidad vía API, presentando la interfaz al usuario.
El carrito existe como entidad en el servidor (commerce engine o microservicio) y cualquier canal que el cliente use (web, mobile, POS, etc.) interactúa con el mismo carrito mediante llamadas API.
Esta arquitectura microservicios + API-first permite que actualizaciones o cambios en la lógica del carrito no requieran modificar la interfaz, y viceversa, brindando gran flexibilidad para evolucionar componentes por separado.
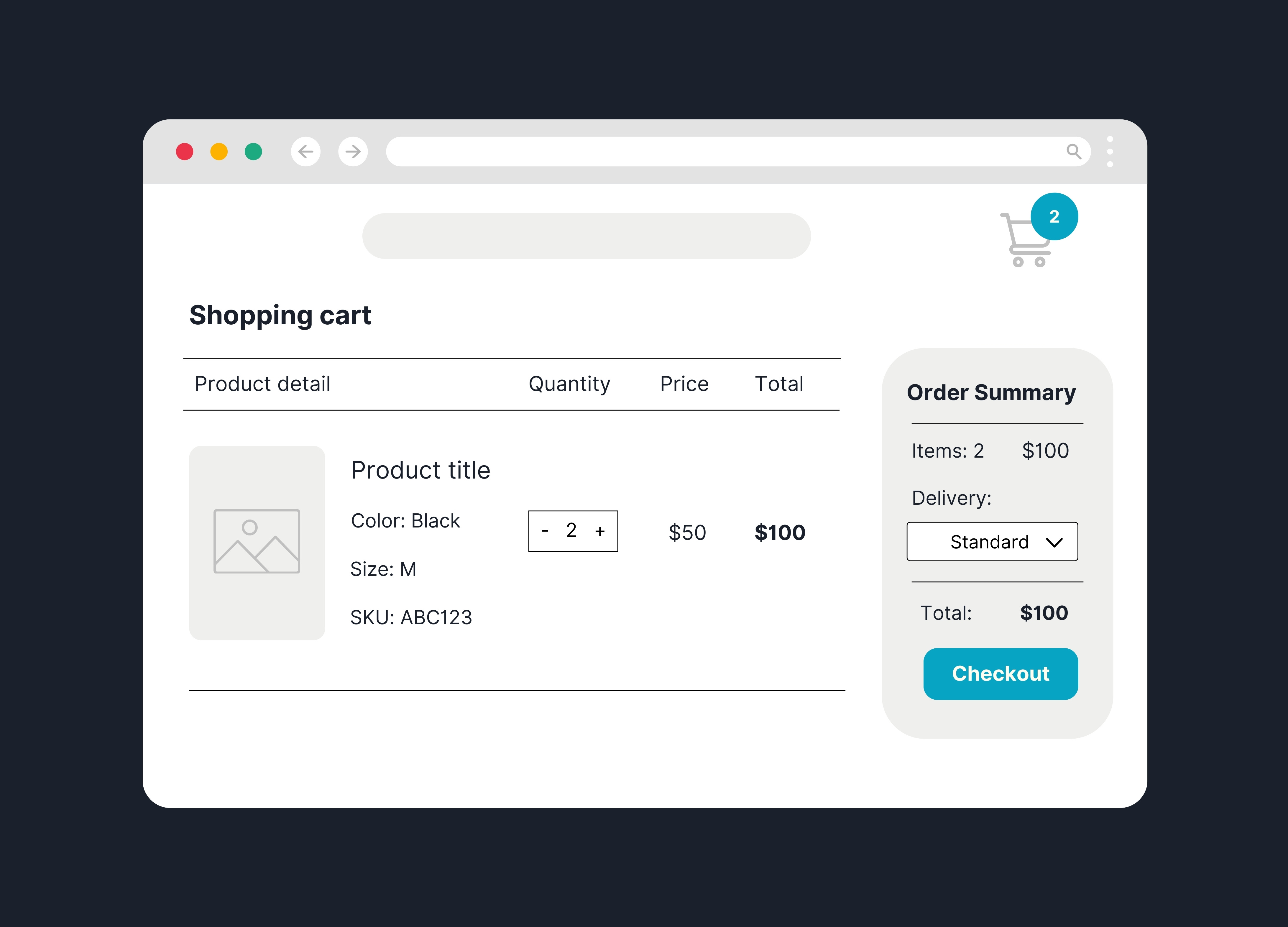
Desde la perspectiva de backend, un commerce engine composable típicamente incluye un servicio dedicado para el carrito (a veces llamado Cart Service o Basket Service). Este servicio maneja las entidades centrales: el Cart y sus Line Items, junto con metadatos (fechas, estado, referencias al usuario o sesión).
En una implementación sencilla, un carrito puede representarse con campos como ID único, ID de usuario (nulo si es anónimo), y una colección de Line Item donde cada uno contiene producto, variante, cantidad y precios calculado.
El servicio de carrito se integra con otros microservicios clave: consulta al servicio de catálogo para obtener datos de productos (nombre, imagen, precio base), verifica con servicio de inventario el stock disponible y reserva unidades si es necesario, y también interactúa con el servicio de promociones para recalcular descuentos aplicables.
Componentes backend y relación con otros sistemas
El carrito actúa como punto central donde confluyen múltiples capacidades: pricing, catálogo, inventario, clientes y checkout.
Una arquitectura bien diseñada tendrá interfaces claras entre el Cart Service y estos módulos.
Por ejemplo:
Al calcular totales, el Cart Service podría llamar a un Pricing/Promotions Service que devuelve los precios con descuentos e impuestos (según reglas definidas). Esto desacopla la lógica de promociones del carrito.
Al agregar un item, se consulta al Inventory Service para reservar stock o al menos validar disponibilidad; algunas implementaciones realizan una reserva de inventario en tiempo real para ese carrito, marcando las unidades como apartadas durante cierto tiempo. Esto es crítico en promociones flash o alta demanda, evitando que otro cliente compre esos artículos mientras el primero aún está comprando.
El Catálogo/PIM provee información de producto necesaria para mostrar en el carrito (descripciones, SKU, tal vez imágenes). En arquitecturas composables, es común almacenar solo referencias (IDs) en el carrito y que el frontend llame a un servicio de catálogo para obtener los detalles visuales. Alternativamente, el Cart Service puede expandir la info vía API.
Con el Checkout/Order Service, el carrito típicamente se transforma en una orden cuando el cliente confirma la compra. En ese momento, el backend puede invalidar el carrito (evitando modificaciones posteriores) y transferir sus datos al módulo de órdenes para procesamiento de pago y cumplimiento logístico. Algunos sistemas tratan el carrito y la orden como la misma entidad en distinto estado (ej. orden con estado “Incompleta” mientras es carrito), simplificando la transición. Otros generan un nuevo objeto Order a partir del Cart. En todo caso, es fundamental que el traspaso incluya re-validar stock y precios por seguridad antes del cobro.
Persistencia del carrito
Dado que los carritos pueden ser efímeros (muchos nunca llegan a convertirse en orden), su persistencia requiere un enfoque eficiente.
Las plataformas headless suelen guardar los carritos en una base de datos rápida (documental o en memoria) optimizada para lecturas/escrituras frecuentes. Por ejemplo, un patrón común es usar caché en memoria o almacenes clave-valor (Redis) para almacenar las sesiones de carrito activas.
Cada vez que el usuario modifica el carrito, se actualiza este almacenamiento rápido, reduciendo la carga sobre la base de datos principal y acelerando la respuesta.
Periódicamente o al convertir en orden, el carrito podría persistirse/actualizarse en un almacenamiento durable (SQL/NoSQL) para registro histórico.
Asimismo, existen políticas de limpieza de carritos abandonados: Commercetools, por ejemplo, limita a 10 millones el número de carritos activos; superado ese umbral, los carritos menos recientes se eliminan automáticamente.
Muchas implementaciones eliminan o archivan carritos inactivos después de X días para liberar recursos (un persistent cart común dura ~30 días si el usuario no compra).
En términos de modelo de datos, conviene evitar la duplicación innecesaria pero también capturar información relevante en el momento de agregar.
Una buena práctica es guardar los precios y descuentos aplicados al añadir el artículo, además del ID de producto, de modo que si el precio cambia en catálogo, el carrito pueda notificar la diferencia (y no cobrar sorpresas). Sin embargo, siempre se recalculará al final para asegurar consistencia.
La arquitectura debe también decidir cuándo calcular los totales: algunos sistemas recalculan en cada modificación del carrito, otros almacenan un subtotal y lo ajustan incrementalmente.
Un enfoque recomendado es calcular en el backend cada vez que se consulta el estado del carrito (y cachear ese resultado unos segundos) para que el frontend obtenga información actualizada sin sobrecargar el sistema.
En resumen, el diseño de un carrito composable implica un delicado balance: modelar el carrito como una entidad de primer nivel con sus propias reglas, manteniéndolo sincronizado con servicios de catálogo, precios, stock y órdenes.
APIs y puntos de integración del carrito
En las arquitecturas headless, todas las operaciones del carrito se realizan a través de APIs. Los commerce engines exponen endpoints REST (y/o GraphQL) para que los frontends gestionen el carrito de forma segura y controlada.
Las operaciones típicas incluyen: crear un nuevo carrito, obtener el carrito actual, añadir un producto, actualizar la cantidad de un Line Item, eliminar un producto, aplicar un cupón o código promocional, calcular totales (si no se hace automáticamente), e incluso vaciar el carrito por completo.
A nivel de integración, esto se traduce en llamadas como:
POST /cart(crear un carrito)GET /cart/{id}(obtener estado)POST /cart/{id}/items(agregar ítem)PATCH /cart/{id}/items/{lineId}(cambiar cantidad)DELETE /cart/{id}/items/{lineId}(remover ítem)
o endpoints específicos para cupones y calcular costos de envío.
Veamos un flujo típico de interacciones API en la experiencia de compra: cuando el usuario hace clic en “Agregar al carrito” en una página de producto, el frontend envía un POST al endpoint de items del carrito. Si el cliente aún no tiene un carrito activo, el commerce engine crea automáticamente un carrito nuevo (esto puede requerir primero un POST /cart vacío según la plataforma).
Luego, el frontend redirige o muestra la miniatura del carrito; para ello realiza un GET del carrito, obteniendo la lista de productos añadidos y los totales.
En la página de carrito, si el usuario modifica cantidades o elimina artículos, se disparan llamadas PATCH o DELETE respectivamente sobre los recursos de item del carrito.
Si agrega un cupón de descuento, el frontend invoca un POST /cart/{id}/coupons con el código, provocando que el backend recalcule los descuentos.
También, se pueden consultar las promociones aplicadas con un GET /cart/{id}/promotions si la plataforma lo ofrece.
Finalmente, al proceder al checkout, se podría llamar a un endpoint específico (POST /cart/{id}/checkout o similar) o simplemente usar el ID del carrito en el flujo de checkout para generar la orden.
Todo este ciclo ocurre mediante llamadas API stateless en las que el cliente (front) envía peticiones y el servidor responde con el estado actualizado del carrito.
Puntos de integración externos
Además de las APIs nativas del commerce engine, el carrito suele integrar APIs de terceros para funcionalidades especializadas.
Por ejemplo, para cálculo de impuestos en ciertas regiones (IVA, impuestos locales en EE.UU.), puede invocar servicios externos o un servicio fiscal propio, enviando la lista de ítems y recibiendo los montos impositivos a agregar.
También para envíos, es común que el carrito consulte a una API de shipping rates cuando el usuario selecciona método de envío, de modo que muestre el costo exacto antes del pago.
En arquitecturas composable, estas integraciones se orquestan a nivel backend: el Cart/Checkout Service orquesta llamadas a terceros y combina los resultados en la respuesta final al frontend.
Por ejemplo, al actualizar el carrito con dirección de envío, el backend podría hacer una llamada a la API de envíos para obtener tarifas y tiempos estimados, añadiéndolos al resumen del carrito.
Límites de las APIs del carrito
Al exponer el carrito vía API, entran en juego consideraciones de rendimiento y seguridad.
Las plataformas imponen límites de llamadas de API (rate limiting) para evitar abusos o picos excesivos de tráfico que afecten la estabilidad. Cuando excedes ese limite recibes un Error (429 Too Many Requests).
Es clave que los integradores diseñen el sistema para administrar estos límites, agrupando operaciones cuando sea posible y evitando llamadas innecesarias. Una técnica recomendada es batching: algunas APIs permiten mandar múltiples operaciones de una sola vez (por ejemplo, añadir 5 ítems en un solo request en vez de 5 llamados separados).
Incluso si no hay un endpoint batch específico, el desarrollador puede programar la interfaz para esperar y enviar actualizaciones agrupadas (p.ej., si el usuario cambia 3 cantidades rápidamente, hacer una sola llamada al final en vez de tres).
Otra estrategia es utilizar caching de resultados en el cliente para reducir consultas repetitivas; por ejemplo, cachear el contenido del carrito en la app y refrescarlo con poca frecuencia. Esto minimiza llamadas API y costos de consumo.
Seguridad de las APIs del carrito
En cuanto a seguridad, las APIs de carrito típicamente requieren autenticación mediante tokens o API keys.
En un escenario headless, el frontend (público) nunca debe exponer credenciales sensibles; en su lugar, utiliza tokens de acceso por usuario o sesión otorgados por el backend.
Por ejemplo, primero el usuario inicia sesión y obtiene un token OAuth/JWT, luego ese token acompaña cada llamada al carrito para asociarla a su identidad y permisos.
Las comunicaciones siempre viajan en HTTPS para proteger los datos (el carrito contiene información potencialmente sensible, como precios personalizados, direcciones, etc.).
Adicionalmente, los commerce engines implementan controles de concurrencia en sus APIs. Muchas plataformas utilizan versionado optimista: cada carrito tiene un version y al intentar modificarlo se debe enviar la versión esperada; si otra modificación ocurrió en medio, la versión ya no coincide y la API devuelve un error de Concurrent Modification, obligando al cliente a obtener el nuevo estado.
El versionado optimista previene que dos actualizaciones simultáneas (por ejemplo desde dos pestañas abiertas) se sobreescriban ciegamente y pierdan datos.
Como responsable de la integración, hay que manejar estos errores reintentando la operación con el estado más reciente del carrito (o informando al usuario si la acción no pudo completarse).
Optimización de costos y performance
Además del caching mencionado, vale la pena considerar el uso de GraphQL cuando esté disponible.
GraphQL permite en una sola consulta obtener tanto el carrito como datos asociados (por ejemplo detalles de productos) en una única llamada, reduciendo el consumo de recursos de múltiples requests separadas.
También se puede aprovechar mecanismos de webhooks o SSE (Server-Sent Events) si el commerce engine los ofrece, para recibir notificaciones de cambios en el carrito sin tener que consultarlo constantemente. Esto es útil en integraciones donde, por ejemplo, el carrito pudiera ser modificado por otro sistema y queremos sincronizar nuestro frontend.
En general, diseñar el consumo de la API pensando en la escala: un sitio con miles de usuarios concurrentes debe evitar polling intensivo del carrito y optar por actualizaciones puntuales (p.ej., refrescar cada 30 segundos el carrito si está abierto, en vez de cada 2 segundos).
Como recomendación final: documentar y entender bien las cuotas y límites de la plataforma escogida (sea CommerceTools, BigCommerce, Commerce Layer u otra). Cada solución composable tiene particularidades en sus APIs (límites de tamaño de carrito, número máximo de líneas, concurrencia, etc.); conocerlos permitirá implementar un frontend que no cause errores inesperados. Por ejemplo, si sabemos que el carrito soporta 100 productos como máximo, podemos prevenir en UI que el usuario agregue más de 100 productos distintos, mejorando la UX y evitando una respuesta de error del backend.
Conclusión
El carrito no es un simple intermediario entre el catálogo y la orden. Es una entidad viva, distribuida, que conversa con múltiples servicios y APIs en tiempo real. Diseñarlo bien, desde la estructura hasta su integración externa, es clave para garantizar una experiencia de compra fluida, segura y escalable. Entender su arquitectura es entender una de las piezas más críticas del composable commerce.